")
Description
onhover.app will take care of the installation and dependencies. Here’s a general overview on how to use TTS Generation WebUI after it loads in the user browser
TTS Generation WebUI
(Bark, MusicGen + AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, MAGNeT)


A powerful web interface that harnesses the latest in text-to-speech (TTS) technology. With this comprehensive toolkit, you have unprecedented control over voice generation.
Github: https://github.com/rsxdalv/tts-generation-webui?tab=readme-ov-file
Features:
-
Multiple TTS Engines: Experiment with a wide array of TTS models and find the perfect voice for your project. Features include:
- Bark: Highly expressive speech synthesis
- MusicGen + AudioGen: Music and sound effect generation
- Tortoise: Versatile TTS with speed and pitch control
- RVC: Realistic voice cloning
- Vocos: Improves the quality of generated speech
- Demucs: Audio and vocal source separation
- SeamlessM4T: Natural reading of ebooks and long-form text
- MAGNeT: High-fidelity audio creation
-
Intuitive Interface: Easily adjust voice settings like pitch, speed, and style. Preview your generated audio directly within the web interface.
-
Text & Audio Editing: Fine-tune generated speech with audio editing tools, or provide custom sound files for even more creative control.
Try on Colab
https://colab.research.google.com/github/rsxdalv/tts-generation-webui/blob/main/notebooks/google_collab.ipynb
Resources
- Bark
- MusicGen + AudioGen
- Tortoise
- Demucs
- SeamlessM4T
Bark
Introduction
Bark is a cutting-edge text-to-speech (TTS) engine known for its expressive and emotional speech synthesis. It stands out for its ability to convey various tones, moods, and inflections with remarkable nuance, making it sound closer to a natural speaker than many other TTS models.
How to Use
-
Locate the Bark Tab: Within the TTS Generation WebUI, find the tab labeled “Bark.”
-
Select a Voice: Choose from a variety of pre-trained Bark voices, each with unique characteristics. Bark offers a diverse range of options, allowing you to select a voice that perfectly matches the tone and style you’re aiming for in your project. Whether you need a serious and authoritative narrator, a friendly and conversational guide, or a character voice brimming with personality, Bark has a voice to suit your needs.
-
Enter Your Text: Type the text you want Bark to say.
-
Adjust Settings (Optional): Experiment with these options in the settings panel to fine-tune the generated speech:
- Voice Style: Alter the emotional tone of the voice (like happy, sad, angry). Use this to set the overall mood and feeling you want to convey.
- History: Use previous audio generations to influence the current one for consistency. This can be helpful for maintaining a consistent voice and tone across longer pieces of text, such as audiobooks or narrations.
- Semantic Tokens: Provide cues and keywords to guide Bark’s delivery. Semantic tokens act like instructions for Bark, allowing you to specify how you want certain words or phrases to be emphasized or delivered.
-
Generate and Preview: Click “Generate” and listen to the audio preview. This allows you to hear how Bark interprets your text and make adjustments before downloading the final audio file.
-
Download: Save your generated speech file.
Use Cases
- Voiceovers: Create engaging voiceovers for videos, presentations, or audiobooks. Bark’s expressive capabilities can significantly enhance the impact and emotional connection of your video content.
- Accessibility Tools: Generate realistic speech for those with speech impairments, allowing them to access information and interact with technology using Bark’s natural-sounding voice.
- Creative Projects: Bring stories, scripts, and artistic projects to life with expressive voices. Bark can add a whole new dimension to your creative projects, breathing life into characters, narrating stories, or setting the mood for your artistic piece.
USP (Unique Selling Point)
- Expressive Speech: Bark excels at conveying emotions and personality within its synthesized speech, making it a powerful tool for creative projects and situations where emotional connection is important.
Limitations
- Occasional Artifacts: Complex prompts or unusual settings can occasionally lead to minor audio glitches. Like any TTS engine, Bark is still under development, and there may be instances where it struggles with particularly challenging prompts.
- Resource Intensive: Depending on your hardware, Bark might require more processing power compared to some other engines. Because of the complexity of its algorithms, Bark may require a computer with a powerful graphics card or processor to generate audio smoothly.
MusicGen + AudioGen
Introduction
MusicGen + AudioGen offers a unique way to generate music and sound effects using text prompts. Tap into AI-powered creativity to produce original soundtracks, ambient soundscapes, or even unique effects for your projects.
How to Use
- Locate the Tab: Find the “MusicGen + AudioGen” tab within the TTS Generation WebUI.
- Enter Your Text Prompt: Describe the kind of music or sound effect you want to create. Here are some tips:
- Be Descriptive: Use adjectives and keywords to guide the generation process (e.g., “uplifting orchestral theme,” “gentle rain on a windowpane,” “futuristic robot sound effect”).
- Structure: Consider specifying basic musical elements like tempo or key signature (e.g., “fast-paced electronic dance music in C minor”).
- Adjust Settings (Optional):
- Length: Define the desired duration of the generated audio.
- Variety: Control how diverse or repetitive the audio should be.
- Generate and Preview: Click “Generate” and listen to the audio preview.
- Download: Save your newly generated music or sound effect file.
Use Cases
- Video Game Soundtracks: Create custom music for indie games or personal projects, giving your game a unique sound and feel.
- Ambient Backgrounds: Generate relaxing soundscapes for meditation, study sessions, or creative work.
- Sound Design: Produce original sound effects for videos, animations, or theatrical productions. MusicGen + AudioGen can provide a source of inspiration and unusual sound elements that would be difficult to find or record.
USP (Unique Selling Point)
- Text-Based Creation: Describe the sounds you want, and the AI takes care of the complex process of composing and generating audio that matches your description. This opens the door to music and sound effect creation even for those who lack musical training or recording expertise.
Limitations
- Unpredictability: AI-generated music can sometimes produce unexpected or slightly “off” sounding results. It might take several attempts to get the desired output. Consider this an experimental tool!
- Limited Complexity: While MusicGen + AudioGen can create impressive results, it might struggle with particularly intricate musical structures or complex sound effects.
Tortoise
Introduction
Tortoise is a versatile text-to-speech (TTS) engine that offers a compelling blend of speed, quality, and control. It excels at generating clear, natural-sounding speech that is well-suited for a wide range of applications. Whether you need a voice for e-learning materials, audiobooks, presentations, or accessibility tools, Tortoise can deliver high-quality audio that effectively communicates your message.
Tortoise is a text-to-speech program built with the following priorities:
- Strong multi-voice capabilities.
- Highly realistic prosody and intonation.
How to Use
- Locate the Tortoise Tab: Within the TTS Generation WebUI, find the tab labeled “Tortoise.”
- Select a Voice: Choose from a variety of pre-trained Tortoise voices. The available options may include male, female, and voices tailored to specific languages or accents. Selecting the right voice can significantly impact the overall feel and tone of your generated speech. For instance, a friendly and approachable voice might be ideal for educational content, while a more authoritative voice could be a better fit for narrating a business presentation.
- Enter Your Text: Type the text you want Tortoise to read aloud.
- Adjust Settings: Tortoise provides several settings for fine-tuning your speech:
- Speed: Control the speaking rate, making the voice sound faster or slower depending on your needs. This can be helpful for adjusting the pace of your audio to match the content or the intended audience.
- Pitch: Adjust the overall highness or lowness of the voice. Raising the pitch can create a more energetic or youthful sound, while lowering it can convey a more serious or authoritative tone.
- Presets: Take advantage of preconfigured settings that combine speed and pitch adjustments. These presets can serve as a starting point for achieving a particular vocal style or can be used for quick generation when you don’t need to make fine-grained adjustments.
- Generate and Preview: Click “Generate” and listen to the audio preview. This allows you to assess the quality and style of the generated speech before downloading the final audio file.
- Download: Save your generated speech file in a standard audio format for use in your project.
Use Cases
- E-learning and Training: Create clear and engaging narration for educational materials, presentations, or training modules. Tortoise’s natural-sounding voices can make complex concepts easier to understand and information more memorable for learners.
- Accessibility Features: Provide audio descriptions of text content for people with visual impairments or reading difficulties. Tortoise can generate speech that is clear, articulate, and easy to follow, promoting greater accessibility to information.
- Prototyping: Quickly generate speech for prototyping voiceovers in presentations, applications, or creative projects. The speed and ease of use of Tortoise make it ideal for creating placeholder audio or testing out different scripts or ideas.
USP (Unique Selling Point)
- All-around Performance: Tortoise strikes a balance between providing good audio quality, offering various customization options, and delivering speech generation at a fast speed. This versatility makes it a powerful TTS engine suitable for a broad range of applications.
Limitations
- Emotional Range: Compared to some other TTS engines like Bark, Tortoise may be less adept at conveying strong emotions or nuanced expressions. If your project requires highly expressive speech, you might consider exploring other options within TTS Generation WebUI.
- Resource Consumption: The resource requirements of Tortoise can vary depending on the selected voice model. Some voice models may be more computationally expensive and might benefit from a computer with a powerful graphics card or processor for optimal performance.
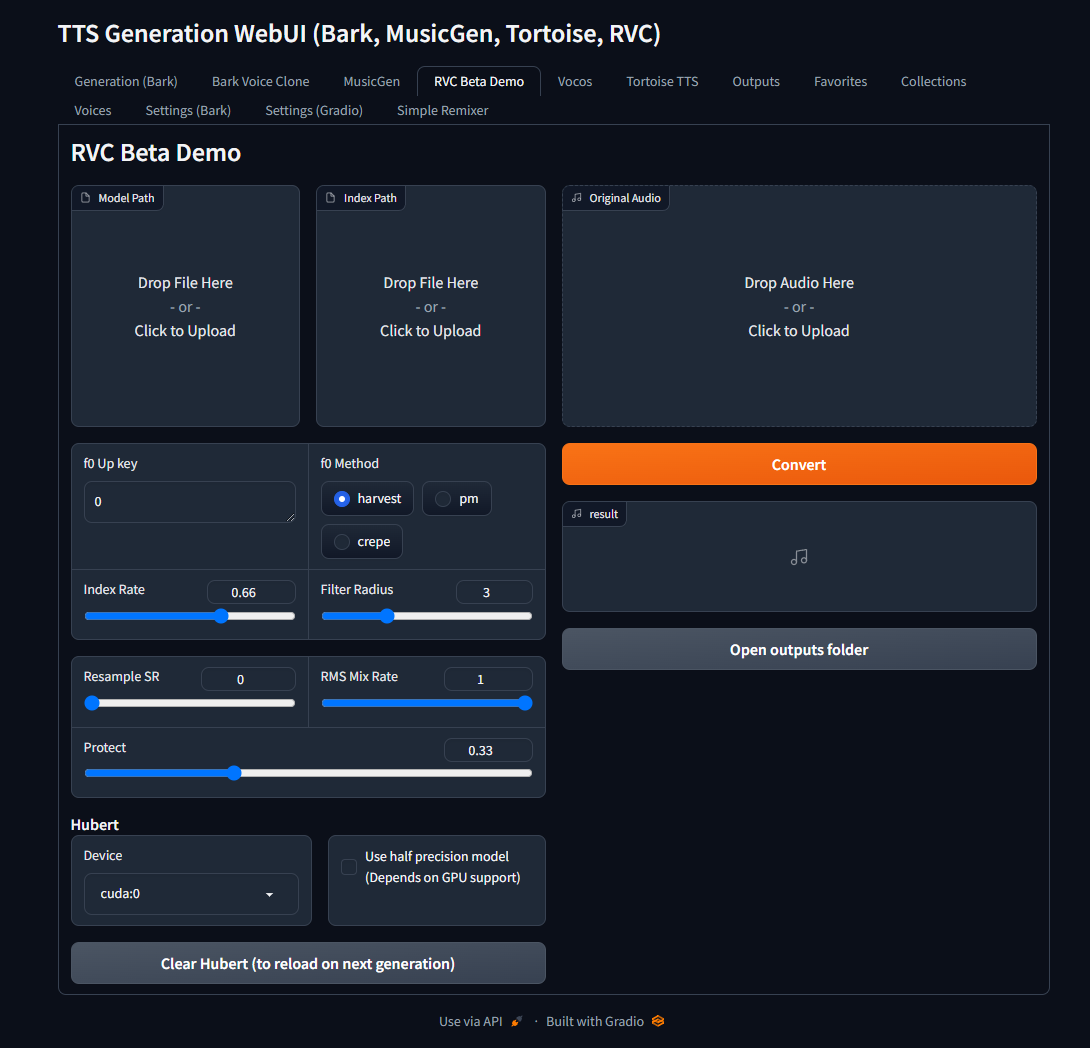
RVC (Retrieval-based-Voice-Conversion)
Introduction
RVC (Retrieval-based-Voice-Conversion) allows you to replicate a specific person’s voice using a sample of their speech. This technology opens exciting possibilities for personalization, creative projects, and even restoring voices for those who lost them due to medical conditions.
How to Use
- Locate the RVC Tab: Find the “RVC” tab within the TTS Generation WebUI.
- Upload/Select Voice Sample: RVC works by analyzing an existing voice sample. You can either upload an audio file containing the voice you want to clone or select a pre-trained voice model if available.
- Quality Matters: The better the quality and clarity of your voice sample, the more accurate the cloned voice will be. Consider factors like background noise, microphone quality, and the length of the sample. Ideally, your sample should contain a variety of spoken words and phrases to provide RVC with a comprehensive representation of the target voice.
- Enter Your Text: Type the text you want the cloned voice to say.
- Adjust Settings (Optional): RVC typically offers options to control the similarity to the original voice and other fine-tuning parameters.
- Similarity: Control how closely the generated speech resembles the original voice. Higher similarity generally improves accuracy but might require a larger voice sample for good results. Experiment with this setting to find a balance between voice fidelity and audio quality.
- Generate and Preview: Click “Generate” and listen to the audio preview. This allows you to assess how well the generated speech captures the characteristics of the original voice.
- Download: Save your newly generated speech file.
Use Cases
- Personalized Voice Assistants: Create a virtual assistant that speaks with your own voice or the voice of a loved one. Imagine a voice assistant that reads audiobooks to your children in your own voice, or helps you navigate your day with familiar and comforting tones.
- Restoring Lost Voices: RVC has the potential to help people who have lost their voices due to illness or injury regain the ability to communicate with their own voice. This technology can offer a powerful tool for people suffering from conditions like ALS or laryngeal cancer, giving them back a sense of control and normalcy in their lives.
- Creative Projects: Use RVC to add a new dimension to audiobooks, videos, or artistic works. Imagine an audiobook narrated in the voice of a historical figure, or a video game character that comes alive with the voice of a renowned actor. RVC opens doors for unique and immersive storytelling experiences.
USP (Unique Selling Point)
- Voice Cloning: Create audio with a cloned voice that closely mimics the nuances and character of a real person’s speech. RVC offers a powerful tool for replicating the specific qualities of a human voice, making it ideal for various applications.
Limitations
- Quality of Sample: The success of RVC heavily depends on the quality and quantity of your voice sample. If your sample is unclear or too short, the generated voice might not accurately reflect the original voice. To achieve optimal results, aim for high-quality recordings with minimal background noise.
- Data & Privacy: RVC requires collecting and using voice data, so it is important that you approach it with responsibility and consider ethical implications. Be mindful of consent when collecting voice samples, and ensure you have the necessary permissions to use someone’s voice for RVC applications.
- Computational Power: RVC can be computationally intensive and may require powerful computers with high-performance graphics cards or processors to ensure smooth operation. Processing large voice samples or using complex voice models can demand significant computing resources.
Important Note: Remember to use RVC responsibly. Ethical considerations around consent and transparency are paramount when utilizing this powerful technology. Always obtain explicit consent before using someone’s voice for RVC, and be transparent about how the cloned voice will be used.
Vocos
Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis
Introduction
Vocos is a fast neural vocoder designed to synthesize audio waveforms from acoustic features. Trained using a Generative Adversarial Network (GAN) objective, Vocos can generate waveforms in a single forward pass. Unlike other typical GAN-based vocoders, Vocos does not model audio samples in the time domain. Instead, it generates spectral coefficients, facilitating rapid audio reconstruction through inverse Fourier transform.
How to Use
- Locate the Vocos Tab: Find the “Vocos” tab within the TTS Generation WebUI.
- Upload/Select Audio: Vocos works with existing audio files. Upload an audio file containing the speech you wish to enhance, or select a previously generated audio clip from within the TTS Generation WebUI workspace.
- Adjust Settings (Optional):
- Noise Reduction: Control the amount of background noise and artifacts removed from the audio. A noisy recording can be distracting and detract from the message being conveyed. Vocos helps eliminate these unwanted elements, leaving behind a cleaner and more focused audio track.
- Smoothing: Adjust how much Vocos alters pronunciations and intonations, creating a more natural flow of speech. This can be particularly helpful for mitigating robotic-sounding speech, a common issue with some TTS engines. By subtly adjusting pronunciations and smoothing transitions, Vocos can make the generated speech sound more like a natural human speaker.
Use Cases
- Enhancing TTS Outputs: Improve the quality of speech generated from other TTS engines within the TTS Generation WebUI. Vocos can serve as a final polish for other TTS models, making them sound more refined and natural. Imagine using a powerful TTS engine for generating a script, but the output lacks that final touch of human quality. Vocos can bridge that gap, transforming the audio from good to great.
- Restoring Old Recordings: Reduce noise and improve the clarity of old or deteriorated voice recordings. You can use Vocos to enhance archival audio or historical recordings. Imagine preserving a cherished recording from your family history, but the audio quality is muffled or filled with background noise. Vocos can help breathe new life into these recordings, making them easier to understand and enjoy.
- Creative Effects: Vocos opens possibilities for subtly altering the characteristics of recorded voices. While its primary focus is on improving quality, Vocos can also be used as a creative tool for slightly manipulating the sound of a voice. For instance, you could use Vocos to make a voice sound slightly breathier or add a touch of reverb for a specific artistic effect.
USP (Unique Selling Point)
- Quality Enhancement Focus: Vocos excels at improving the overall audio quality of speech synthesis. It can reduce artifacts and add a human-like quality to a generated voice. If refining audio output is your primary concern, Vocos is a powerful tool to consider.
Limitations
- Subtle Enhancements: While Vocos can significantly improve the quality of generated or recorded speech, it’s important to manage expectations. Vocos won’t make a poor quality TTS engine sound completely indistinguishable from a real human speaker. Vocos focuses on refinements and smoothing out imperfections, rather than dramatically altering the nature of a voice or compensating for significant problems in the original audio. For instance, if the original recording has a weak or distorted signal, Vocos may not be able to entirely overcome these limitations.
Demucs
Introduction
Demucs is a powerful tool for audio source separation. It harnesses the power of artificial intelligence to isolate different elements within an audio track, such as vocals, drums, bass, and other instruments. This technology opens up a world of possibilities for remixing, content creation, audio editing, and even scientific analysis of music.
How to Use
- Locate the Demucs Tab: Find the “Demucs” tab within the TTS Generation WebUI.
- Upload Audio File: Upload the audio file that you want to process with Demucs. Supported formats typically include .wav, .mp3, and others depending on the specific Demucs integration.
- Select Tracks to Isolate: Choose the specific tracks you want to separate from the audio. Common options might include vocals, drums, bass, and other instruments. Demucs can also attempt to isolate a wider array of instruments, depending on the complexity of the audio and the capabilities of the specific Demucs model being used.
- Adjust Settings (Optional):
- Model: Some Demucs integrations might offer different models or algorithms trained for specific tasks. Select the model that best suits your needs. For instance, there might be models focused on isolating vocals from music, or others designed to separate multiple instruments in a complex orchestral piece.
- Aggressiveness: Control how intensely Demucs separates the tracks. Experiment with this setting to find the right balance between clean separation and potential audio artifacts. Higher aggressiveness might result in better isolation of the target tracks, but it can also introduce unwanted noise or distortions into the separated audio.
- Process and Preview: Click to process the file with Demucs settings. You can preview the separated tracks before downloading to assess the quality of the separation. This allows you to fine-tune the settings or select a different model before creating the final audio files.
- Download: Save the separated tracks individually as audio files. These audio files can then be used in your project or for further editing and processing within your digital audio workstation.
Use Cases
- Music Remixing and A Cappella Creation: Isolate vocals, instrumentals, or specific beats to create remixes, mashups, DJ sets, or a cappella versions of songs. Demucs lets you extract the building blocks of a song, allowing you to experiment with different arrangements and creative combinations.
- Karaoke Track Creation: Remove vocals from a song to create karaoke tracks for practice or entertainment purposes. Demucs can provide high-quality instrumental backing tracks that can be used for singing along to your favorite songs.
- Sample Extraction for Music Production: Isolate specific sound elements or musical phrases from a recording for use in music production or sound design. Demucs offers a powerful tool for capturing interesting sounds or samples from existing recordings to incorporate into your own creative projects.
- Audio Cleanup and Restoration: Reduce background noise, isolate specific instruments, or remove unwanted sounds from an audio recording. Demucs can help to enhance the clarity and focus of an audio recording by removing distracting elements or separating vocals from background noise.
- Musicological Analysis: Demucs can be a valuable tool for musicologists and music researchers. By separating the different components of a recording, researchers can gain insights into the musical structure, instrumentation, and mixing techniques used in a particular piece.
USP (Unique Selling Point)
- AI-Powered Separation: Demucs leverages sophisticated deep learning algorithms to isolate different audio sources within a single audio track. This advanced technology allows for separation that would be difficult or impossible with traditional audio editing techniques, which often rely on manual processing or frequency-based separation methods.
Limitations
- Imperfect Separation: While Demucs is remarkably powerful, the separation might not be flawless, especially in complex mixes. Complex musical arrangements or recordings with low audio quality can introduce artifacts into the separated tracks, or some instruments might bleed into other tracks. It’s important to manage expectations and consider Demucs output as a starting point for further edits and adjustments within your digital audio workstation.
- Computational Demands: Depending on the model and settings used, Demucs can be computationally demanding. Processing complex audio files or using high-quality separation models might require a computer with a powerful graphics card or processor for smooth operation.
SeamlessM4T
Introduction
SeamlessM4T shines as a multilingual text-to-speech (TTS) engine, adept at reading aloud text in various languages with remarkable fluency. Its capabilities extend beyond simple translation, offering smooth and natural transitions between languages, making it ideal for handling long-form content like ebooks and articles that seamlessly blend multiple languages. Whether you’re creating educational materials for a global audience, enhancing accessibility tools for multilingual users, or crafting unique artistic experiences that weave together different languages, SeamlessM4T equips you with a powerful and versatile solution.
How to Use
-
Locate the SeamlessM4T Tab: Find the designated “SeamlessM4T” tab within the TTS Generation WebUI.
-
Input Your Text: Paste or type the text you want SeamlessM4T to convert into spoken audio. SeamlessM4T excels at handling multilingual content, so you can include text passages in multiple languages without needing any special formatting.
-
Select Voices (Optional): In most cases, SeamlessM4T automatically selects suitable voices for each detected language within your text. However, you might have the flexibility to manually assign specific voices to different sections of your text for enhanced control over the final output.
-
Adjust Settings (Optional):
- Speech Customization: Fine-tune the reading style by adjusting the speaking speed and pitch to match your preferences.
- Language Transitions: SeamlessM4T offers control over how the TTS engine transitions between languages within your text. You can tailor this setting to achieve a smoother and more natural flow, especially for lengthy passages that incorporate multiple languages.
-
Generate and Preview: Click the “Generate” button to initiate the text-to-speech conversion process. SeamlessM4T will generate an audio preview, allowing you to listen to the spoken version of your multilingual text before downloading the final audio file.
-
Download: Save the generated speech file to your device in a standard audio format for later use in your project.
Use Cases
-
Accessibility Champion: SeamlessM4T breaks down language barriers, making written content accessible to a wider audience by converting text into spoken form across multiple languages. This can empower people with reading difficulties or those who speak languages not natively supported by the written content.
-
Multilingual Content Powerhouse: Breathe life into multilingual websites, documents, and user interfaces with the help of SeamlessM4T. This technology bridges the language gap, making your content available to a global audience and fostering a more inclusive user experience.
-
Language Learning Ally: SeamlessM4T serves as a valuable language learning tool. Listen to the correct pronunciation of words and phrases in your target language while following along with the written text. This can significantly enhance your language learning journey by combining visual and auditory reinforcement.
USP (Unique Selling Point)
SeamlessM4T stands out for its exceptional proficiency in handling multilingual text-to-speech. Its ability to seamlessly transition between languages and deliver natural-sounding speech across diverse languages makes it a game-changer for applications that require multilingual audio generation.
Limitations
- Supported Languages: While SeamlessM4T offers a wide range of languages, it may not support all languages perfectly. The quality and naturalness of the speech output can vary depending on the specific language being used.
- Beta Technology: SeamlessM4T is still under development, and its capabilities are constantly evolving. As with any new technology, there might be occasional glitches or inconsistencies in the generated speech.
- Limited Voice Options: The availability of voice options for each supported language might be limited compared to single-language TTS engines. This is because creating high-quality multilingual voices is a complex task.
MAGNeT
Introduction
MAGNeT is a cutting-edge text-to-speech (TTS) engine designed to deliver the highest-quality speech synthesis. It stands out for its ability to generate audio that is remarkably close to natural human speech, including subtle intonations, pauses, and realistic phrasing. This makes MAGNeT ideal for situations where clarity, nuance, and emotional conveyance are critical for the success of your project.
How to Use
- Locate the MAGNeT Tab: Within the TTS Generation WebUI, find the tab labeled “MAGNeT.”
- Select a Preset: MAGNeT often offers various presets for different voice styles, accents, and languages. Choose a preset that aligns with your project’s requirements. If you’re unsure, start with a general-purpose preset and experiment!
- Enter Your Text: Input the text you want MAGNeT to speak.
- Adjust Settings (Optional):
- Emotion: Fine-tune the emotion portrayed in the generated speech. Options might include happy, sad, neutral, etc.
- Emphasis: Use emphasis marks (like exclamation points or commas) to control the intonation and stress in the generated speech. You can also experiment with adding phonetic pronunciation markers for even more precise control over how specific words or phrases are delivered.
- Generate and Preview: Click “Generate” and listen to the audio preview.
- Download: Save your newly generated speech file.
Use Cases
- Professional Audiobooks: Create high-quality audiobook narrations with MAGNeT. Its ability to convey tone and emotion can add a new dimension to audiobook storytelling, rivaling recordings from professional voice actors. Listeners will be captivated by the natural flow and expressiveness of the narration, enhancing their overall audiobook experience.
- Animation & Video Voiceovers: Bring characters to life or create immersive video narrations with naturally expressive voices. MAGNeT’s quality ensures your audio tracks blend seamlessly and elevate video content. Characters will speak with believable voices that resonate with viewers and strengthen the emotional impact of your animation or video project.
- High-Fidelity Accessibility Tools: Use MAGNeT for applications where clarity and natural-sounding delivery are paramount. Make digital content accessible to a wider audience by providing high-quality audio descriptions powered by MAGNeT. Visually impaired users will benefit from audio descriptions that are articulate, engaging, and closely mirror the natural flow of human speech.
USP (Unique Selling Point)
- Umatched Quality: MAGNeT aims to set the benchmark for realistic TTS output. It focuses on generating speech that is indistinguishable from a human speaker, making it ideal for professional applications or creative projects where natural-sounding voices are essential.
Limitations
- Computational Requirements: MAGNeT may demand significant processing power. Smooth audio generation could require a powerful computer with a high-performance graphics card or processor.
- Limited Customization: Compared to some other TTS engines, MAGNeT might offer fewer detailed customization settings. Its primary focus is producing the most natural-sounding speech, limiting users’ ability to heavily alter the voice characteristics. However, the provided presets and basic controls should be sufficient for most use cases.




Reviews
There are no reviews yet.